Your Prompt Has Nine Fasteners
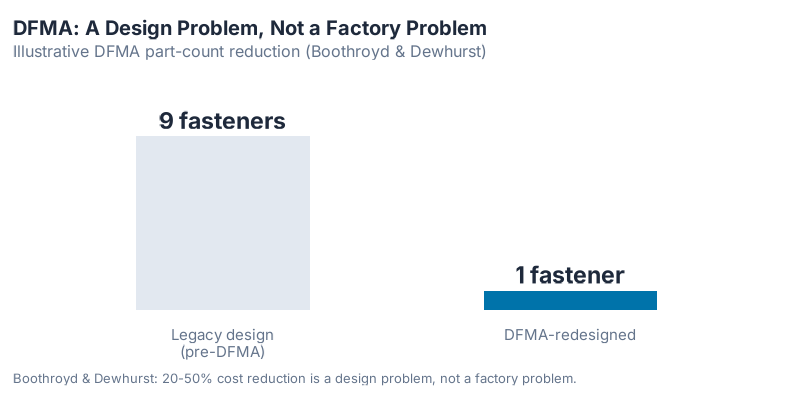
In 1985, IBM set out to redesign its Proprinter — the dot-matrix printer competing head-to-head with the Epson MX80. Engineers working from the Design for Manufacturability and Assembly methodology developed by Geoffrey Boothroyd and Peter Dewhurst at the University of Massachusetts asked a simple, brutal question: does this product need all these parts?
The answer was no. IBM’s DFMA redesign eliminated all fasteners and reached the theoretical minimum part count. The competing Epson design required approximately 111 more parts for the same function. Assembly time came in at 170 seconds. The Proprinter cost less to build, less to fail, and less to service — and none of that improvement came from the factory. It came from the design. (Dewhurst & Boothroyd, "Design for Assembly in Action," Assembly Engineering, 1987.)
Their insight became the discipline of Design for Manufacturability and Assembly (DFMA): manufacturing cost is not a factory problem. It is a design problem. By the time the product reached the factory floor, 70–80% of its cost was already locked in by design decisions made weeks or months earlier.
This idea spread fast. Ford. IBM. Motorola. Procter & Gamble. Industry after industry discovered that they had been optimizing their factories while the real waste was upstream, in the design stage. DFMA delivered 20–50% cost reductions across automotive and electronics — not by building better robots, but by designing simpler products.
In 2026, we have the exact same problem with AI.
The reason your AI assistant keeps missing the point isn’t Claude, GPT, or Gemini. It is that the prompt you wrote — the document you handed it, the SOP you uploaded, the ticket you assigned it — has the communicative equivalent of nine fasteners. It assumes a reader who already knows the unspoken rules, tolerates ambiguity, can infer missing context, and will ask for clarification when confused.
LLMs are not that reader. And that mismatch is costing organizations millions in failed pilots, wasted tokens, and re-work.
The fix is not smarter models. It is a new discipline: Design for AI (DFAI) — treating the way we write, structure, document, and hand off work as engineering artifacts designed to be executed by a literal machine. By the end of this post, you will have 7 concrete rules you can apply to the next prompt you write.
Section 1 — DFMA in One Minute
Before the analogy, the source material. DFMA is a methodology developed by Boothroyd, Dewhurst, and later Knight for analyzing product designs from the perspective of the manufacturing process that will produce them. The core idea: most production cost is determined at design time, not on the factory floor.
The canonical rules (Boothroyd & Dewhurst, Product Design for Manufacture and Assembly, 1994):
- Minimize part count — every part is a potential failure, assembly step, and inventory item
- Self-locating features — parts should position themselves; don’t rely on the assembler to interpret
- Eliminate adjustments — variation in assembly should be handled by design, not by the worker
- Single-direction assembly — all parts insert from the same direction; no flipping, no reorientation
- Standardize fasteners — fewer fastener types means fewer tools, fewer errors, faster assembly
- Poka-yoke (mistake-proof) — design parts so they can only go in the correct way
- Design for ease of handling — parts that are easy to pick up, orient, and place
- Eliminate secondary operations — no rework, no post-assembly adjustments
The results were consistent across industries: 20–50% cost reductions, with the biggest gains coming not from process optimization but from part-count reduction. Less to assemble = faster assembly, fewer defects, lower cost.
The most important insight from DFMA was philosophical: it forced engineers to think about downstream processes before the design was frozen. The people writing the spec had to understand how the spec would be executed — by a machine, with no ability to fill in gaps.
Sound familiar?
Section 2 — Why Your Prompts and Pilots Stall
The numbers are uncomfortable. Only 4% of companies have developed the AI capabilities needed to consistently generate significant value from it (BCG, Where’s the Value in AI?, 2024). Gartner predicts organizations will abandon 60% of AI projects through 2026 for lack of AI-ready data. These are not numbers about AI capability. They are numbers about AI readiness — and specifically, about the quality of the inputs organizations hand to AI systems.
The root causes, framed honestly, are all design failures:
LLMs don’t hold ambiguity open — they commit. Research on LLM ambiguity (arXiv 2505.11679, 2025) confirms what practitioners observe daily: when faced with an ambiguous input, LLMs don’t hold multiple interpretations open the way a human colleague might — they commit to one reading and generate forward. The ambiguity does not surface as confusion; it surfaces as a confidently wrong answer.
46% of organizations identify operations as their most tribal-knowledge-dependent function (Lucid.co AI Readiness Report, 2025). That knowledge lives in someone’s head. It is never written down, never specified, never externalized. When an LLM processes a document that assumes that tribal knowledge, it is operating with a missing assembly manual.
More context is not the same as better context. Anthropic’s context engineering research (2025) makes the point directly: it is not about filling the context window, it is about filling it with the right information. Structured, high-signal context systematically outperforms a raw dump of documents — regardless of how large the context window is.
11,000 Baby Boomers retire daily (Alliance for Lifetime Income, 2024), taking with them the institutional knowledge that most organizational documentation assumed was already in the reader’s head.
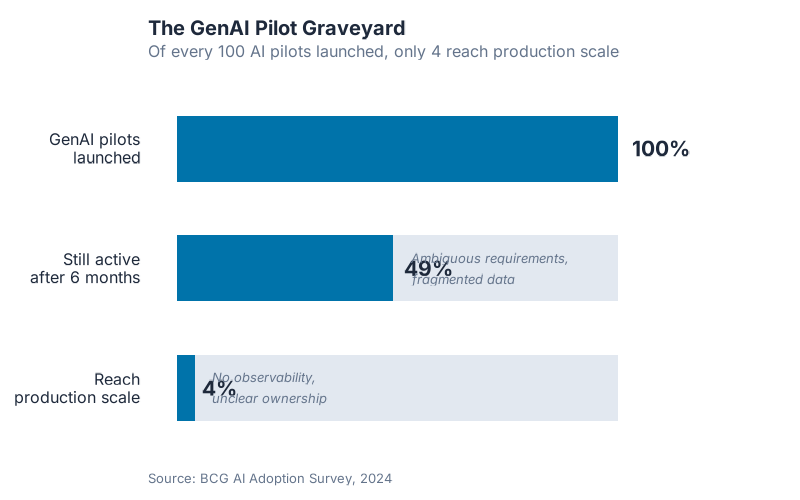
None of these are AI failures. They are failures of design — of the inputs, the documents, the prompts, the processes that LLMs are asked to execute. You cannot prompt your way out of a system that was never designed to be read by a literal machine.
This post is not about prompt engineering techniques, which I covered in Prompting Just Split Into 4 Different Skills. It is not about the history of prompting methods from 2020 to 2026, which is in Anthropic Just Killed One of Its Own Prompting Tricks. And it is not another argument that structured frameworks improve your prompts — that case was made in The $50,000 Prompt using McKinsey methodology.
DFAI is a different lens. It is not about which technique you use when you open a chat window. It is about the design quality of everything the LLM reads — before it writes a single token.
Section 3 — The 7 Principles of Design for AI

Each principle below maps to a DFMA rule, names the DFAI equivalent, cites the research behind it, and gives a concrete before/after example across different knowledge-work domains.
Principle 1: Eliminate Ambiguity
DFMA analogue: Poka-yoke / mistake-proofing — design parts so they can only be assembled correctly.
DFAI rule: Write prompts and documents with exactly one reasonable interpretation. If a human reader could parse it two ways, an LLM will pick one without telling you which.
Why it matters: arXiv 2505.11679 (2025) documents what practitioners already feel: LLMs bias toward generating one interpretation among many for an ambiguous input, rather than holding alternatives open. In practice, vague verbs ("analyze," "improve," "summarize"), unspecified audiences, and missing constraints are not just stylistic weaknesses — they are architectural failure points in your input design.
The fix is not wordsmithing. It is adding what DFMA calls a locating feature: a constraint that makes the wrong interpretation physically impossible. Specify audience, scope, format, tone, and exclusions explicitly, and the interpretation space collapses to one.
❌ Before: "Write a follow-up email to the client about the delay."
✅ After: "Write a 3-paragraph email to our enterprise client contact (technical buyer, skeptical tone expected). Topic: our 2-week delivery delay on Order #8821. Paragraph 1: acknowledge the delay and take responsibility. Paragraph 2: specific cause (supplier lead time extension, not internal). Paragraph 3: revised delivery date (April 28) + what we are doing to prevent recurrence. Tone: direct, professional, no apologies after the first sentence. Do not offer discounts or concessions."
Principle 2: Externalize Tribal Knowledge
DFMA analogue: Standardize to a single source of truth — eliminate process variation by writing it down, once, definitively.
DFAI rule: Every piece of knowledge the LLM needs to execute correctly must exist as an artifact in the prompt or context. If it lives only in someone’s head, it does not exist for the model.
Why it matters: Lucid.co’s 2025 AI Readiness Report found that 46% of organizations identify operations as their most tribal-knowledge-dependent function. When that knowledge is missing from the context, LLMs fill the gap with pattern-matching from their training data — which is often generic and occasionally wrong. The result is plausible-sounding output that violates internal conventions the model had no way to know about.
❌ Before: "Write a Python function that follows our team’s style."
✅ After: "Write a Python function that follows these team conventions: (1) type hints on all function signatures, (2) Google-style docstrings, (3) errors raise custom exceptions from
exceptions.py, never bareException, (4) no logic in__init__files, (5) max function length 40 lines. Function to write: [spec follows]."
Principle 3: Chunk and Label
DFMA analogue: Single-direction assembly — all components should load from the same direction, with clear sequencing.
DFAI rule: Break complex inputs into labeled, discrete sections. Give every section a clear header. Long undivided documents are the textual equivalent of an assembly with no orientation markers.
Why it matters: Anthropic’s context engineering research (2025) states it directly: find the smallest set of high-signal tokens that maximize the likelihood of the desired outcome. A focused, well-structured context block outperforms an unstructured document dump — regardless of raw token count. The information architecture of the context is a variable that determines output quality, not just the information itself. Chunked, labeled inputs reduce the model’s cognitive overhead in parsing, which increases the precision of generation.
❌ Before: "Here is the research paper, three analyst reports, and some notes I took last week. Can you extract the main themes and any contradictions?"
✅ After:
"## Task: Extract themes and contradictions across 4 sources.Source 1 — Research paper (Smith et al., 2024): [paste]
Source 2 — Analyst report (Goldman, Feb 2026): [paste]
Source 3 — Analyst report (Bernstein, Mar 2026): [paste]
Source 4 — My notes (field interview, Apr 2026): [paste]
Output format: (a) 3–5 themes all sources agree on, (b) 2–3 points where sources contradict, (c) one claim in my notes not corroborated elsewhere."
Principle 4: Prefer Structured Over Narrative
DFMA analogue: Machine-readable format — parts described in engineering drawings, not prose descriptions, because machines need coordinates, not stories.
DFAI rule: Wherever the input data has structure, preserve it explicitly. Tables, JSON, bullet lists, and key:value pairs outperform equivalent prose for any downstream computation or extraction task.
Why it matters: As of 2025, over 600 websites had adopted the /llms.txt standard (Howard, Answer.AI, 2024) — a structured, Markdown-formatted file designed to give LLMs a machine-readable summary of a site’s content rather than a scraped prose page. The premise is the same as a CAD drawing versus a verbal description: structured formats are unambiguous by construction.
SCM example (RFQ intake):
❌ Before (narrative RFQ): "We’re looking for a supplier who can provide approximately 10,000 units of our standard M8 bracket, ideally in Q3, with delivery to our Munich facility. Pricing should be competitive and we need reliable quality."
✅ After (structured RFQ fields):
Part number: M8-BKT-001 Quantity: 10,000 units Delivery: 2026-09-01 (hard), Munich (plant code MU-03) Spec: DIN 912, Grade 8.8, zinc-plated Price target: ≤ €0.42/unit Required certificates: EN 15048, ISO 9001 Bid deadline: 2026-05-15
The structured version eliminates the interpretation layer entirely. The LLM — or the human — reading the second version has no decisions to make.
Principle 5: Make State Explicit
DFMA analogue: Self-locating features — a part that knows where it belongs, without the assembler having to decide.
DFAI rule: Never rely on implicit context accumulated across a conversation or workflow. In every handoff, every new context window, every new session, state the current state explicitly.
Why it matters: Anthropic’s Building Effective Agents (2024) identifies implicit state assumptions as a primary source of agentic failure. In multi-step workflows, agents do not automatically carry forward information from prior steps unless that information is explicitly present in the current context. A human colleague can reconstruct context from memory; an LLM can only work with what is in front of it.
❌ Before (continuing a conversation from yesterday): "Ok, continue with the analysis you started."
✅ After: "## Current state: We are mid-way through a competitive analysis for a new SaaS pricing decision. Completed: market segment sizing (see table below), competitor price benchmarking for Tier 1 and Tier 2 segments. Not yet done: Tier 3 pricing, sensitivity analysis, recommendation. Next step: analyze Tier 3 pricing options using the same framework as Tier 2 (attached). Constraint: target gross margin ≥ 72%."
Principle 6: Standardize the Human↔Agent Handoff
DFMA analogue: Standardized fasteners — fewer fastener types means fewer tools, fewer errors, fewer cognitive switching costs.
DFAI rule: Define a consistent, reusable protocol for how humans hand tasks to AI agents and receive results back. Ad-hoc handoffs accumulate variation; variation accumulates errors.
Why it matters: Klein and Hoffman’s work on human-AI teaming (2025) identifies interface consistency as a critical variable in collaborative performance. When humans use different prompting formats, different output schemas, and different escalation procedures across tasks, teams lose the ability to review, audit, and improve AI outputs systematically. A standardized handoff is not a constraint on creativity — it is what makes quality reproducible.
❌ Before (ad hoc): "Hey, can you review this contract and flag anything weird? Also check if the payment terms are ok. Let me know what you think."
✅ After (standardized handoff template):
TASK: [one-line description] CONTEXT: [relevant background — max 200 words] CONSTRAINTS: [hard limits the output must respect] OUTPUT FORMAT: [exact structure, e.g., JSON schema or Markdown template] ESCALATION CRITERIA: [conditions under which the agent should stop and flag for human review]
Principle 7: Observability First
DFMA analogue: Mistake-proofing + cost visibility — design so that errors are visible immediately and cheaply, not after they have propagated downstream.
DFAI rule: Design your AI workflows to fail loudly and visibly. Build evals, assertions, and output validators before you scale. Unobservable AI output is a design defect, not an operational risk.
Why it matters: arXiv 2512.12791 (2024) argues that agentic AI evaluation must go beyond binary task completion — behavioral failures invisible to "did it finish?" metrics only surface through comprehensive assessment of tool use, memory management, and environmental interaction. An AI agent that confidently produces wrong output with no visibility mechanism is the LLM equivalent of an assembly line with no quality gate: the defects ship.
❌ Before: Deploy a document classification agent, review a sample of outputs monthly, fix issues as they surface.
✅ After: Define expected output schema before deployment. Write 20 test cases with known correct answers. Instrument the agent to log confidence scores and flag low-confidence outputs for human review. Set a threshold (e.g., ≥95% classification agreement on the test set) as a go/no-go criterion. Review the eval dashboard weekly; trigger investigation if accuracy drops >2 percentage points.
Section 4 — Three Things DFMA Didn’t Warn Us About
DFMA was a manufacturing discipline. It was not designed for the specific pathologies of knowledge work. Three inversions surprised even DFMA devotees when they tried to port the discipline to AI.
1. Humans must become more literal, not agents more human.
DFMA placed the burden on engineers: design the product to suit the process. DFAI places the burden on knowledge workers: write for a reader that cannot infer intent.
This is culturally harder than it sounds. Most professional writing — business emails, strategy documents, meeting notes, project briefs — is proudly ambiguous. It is written for human colleagues who share context, who ask questions, who can read between the lines. Ambiguity in that context is not a bug; it is efficient shorthand.
An LLM has none of those social repair mechanisms. It cannot ask a clarifying question in the middle of executing a 35-minute agentic task. It reads what is in front of it, commits to one interpretation, and generates forward. The cultural ask of DFAI — "write as if your reader is intelligent but has no unspoken context, cannot infer, and will not ask" — runs directly against how most professionals have been trained to communicate. That is not a technical problem. It is an organizational change management problem.
2. Eliminating steps beats optimizing them.
The DFMA version of this insight was that the best cost reduction often came from removing a part entirely, not redesigning it. The same inversion applies to DFAI.
When a prompt fails, the instinct is to engineer a more sophisticated prompt for the same underlying task structure. Add more instructions. More examples. More constraints. More chain-of-thought scaffolding.
Often the right move is simpler and harder: redesign the task so the agent has fewer decisions to make. Fewer branches, fewer interpretations required, fewer opportunities to go wrong. The best DFAI move is frequently "restructure the upstream input so this decision doesn’t need to be made at all" — not "write a cleverer prompt to handle a structural mess."
This matters because it shifts the intervention point. Prompt optimization is local. Input redesign is systemic. Organizations that only ever optimize prompts are iterating around the edges of a design problem they have not named.
3. Your notes, docs, and templates are now production infrastructure.
The moment an LLM reads something, the quality of that thing becomes the ceiling of the output.
Your README. Your onboarding document. Your meeting-notes-to-CRM template. Your procurement policy SOP. Your style guide. Your RFQ form. All of them are now executable substrate, not help files. If they are vague, your AI outputs will be vague. If they contain outdated information, your AI outputs will be confidently wrong. If they assume tribal knowledge, your AI outputs will silently omit what was never written down.
This is the organizational consequence that most AI adoption strategies miss entirely. The bottleneck is not model capability. It is documentation quality — and documentation quality has been neglected for decades precisely because human readers could compensate for it. LLMs cannot.
The 11,000 Baby Boomers who retire daily (Alliance for Lifetime Income, 2024) are not just taking their experience with them. They are making visible, for the first time, just how much organizational functioning depended on knowledge that was never written down at all.
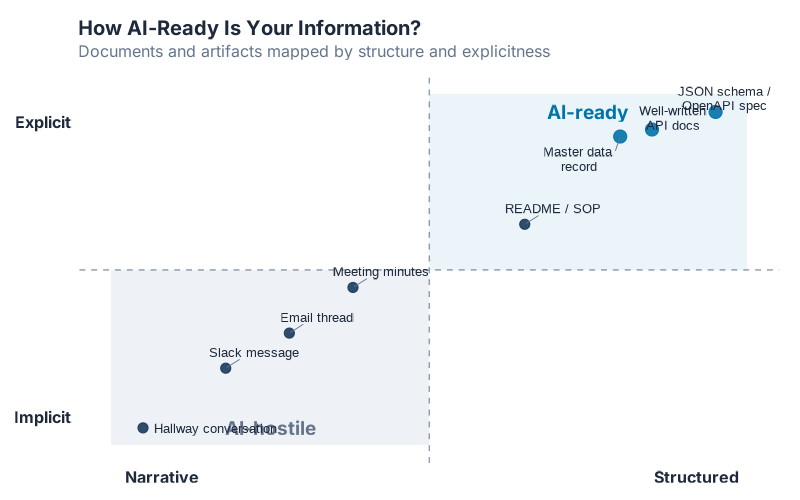
The quadrant above plots common workplace artifacts on two axes: how explicit they are (does the document contain everything the reader needs?) versus how structured they are (is the information machine-readable?). Well-written API documentation and structured data schemas sit in the upper-right. Tribal knowledge and watercooler conversation sit in the lower-left. Most organizational documentation clusters somewhere in the middle — written for humans who could fill in the gaps, and now insufficient for machines that cannot.
Section 5 — Where the Analogy Breaks
Every analogy has limits. Here are DFAI’s:
DFMA designs for deterministic processes. LLMs are probabilistic. DFAI can reduce ambiguity, improve input structure, and make outputs more consistent — but it cannot eliminate non-determinism. Two identical prompts may produce different outputs. Design reduces variance; it does not eliminate it. Build your workflows accordingly: treat AI output as a high-quality first draft that requires a defined review step, not a guaranteed result.
DFMA’s improvements are durable. DFAI requires continuous re-evaluation. A part designed to DFMA principles in 1990 still works the same way in 2026. A prompt tuned for Claude 3.5 may behave meaningfully differently on Claude 4, GPT-5, or a fine-tuned domain model. Model versions change frequently, and optimization against a specific model can become a liability when that model is deprecated. DFAI principles should be robust to model changes, but specific prompt implementations should be re-validated when models change.
Works best for structured, repeatable work. DFAI is powerful for high-volume, repeatable knowledge tasks: document classification, RFQ intake, report generation, ticket triage, data extraction, meeting summarization. It is weaker for genuinely ambiguous, creative, or relationship-driven work where the right output is not specifiable in advance. Know the difference before you apply the discipline.
Some rules are artifacts of current constraints. Chunking and context minimization are partially driven by today’s context-window and attention limitations. Those constraints may relax significantly in the next two to five years. The underlying principle — structured inputs outperform unstructured inputs — is robust. The specific implementation guidance may need updating.
Section 6 — The 5-Step DFAI Audit You Can Run This Week
Theory without a handle is a decoration. Here is how to apply DFAI immediately — two variants.
A. For individuals and prompt authors
-
Take your last 10 chat prompts. Count how many contain a word or phrase that has more than one reasonable interpretation. Be honest: "analyze," "improve," "review," "summarize" almost always fail this test.
-
Pick the worst offender. The one most likely to generate a plausible-but-wrong response because the goal was underspecified.
-
Rewrite it to pass the one-interpretation test. Add: audience, scope, constraints, output format, and at least one explicit exclusion (what the model should not do).
-
Add a state block at the top. Even for single-turn prompts: what is the current situation, what has already been done, what does "done" look like.
-
Save it as a reusable template. Strip out the specifics and leave the structure. You have just built a DFAI-compliant part — one that can be reused, improved, and handed to a colleague without explaining what you meant.
B. For teams and workflow owners
-
Pick one high-volume process — RFQ intake, ticket triage, invoice coding, meeting notes → CRM, contract review. Pick the one where AI output quality is most variable.
-
Map every implicit decision. Walk through the process step by step. Every place where a human thinks "obviously, I would…" — that is a gap in the design. Write them all down.
-
Score each gap: Can it be written as an explicit rule? (Yes / No / Maybe.) The "yes" pile is your DFAI backlog.
-
Identify the 3 biggest nine-fastener moments — places where the design itself could eliminate a step, not just improve it. Where does the process require the LLM to make an inferential leap that good input design could eliminate entirely?
-
Redesign one this quarter. Not a transformation program. One process, one rule, one structured template. Measure the output quality difference. Then do the next one.

Show R Code
# =============================================================================
# Design for AI (DFAI) — Image Generation
# =============================================================================
# Generates all 5 visualizations for the "Design for AI" (DFMA → DFAI) post.
#
# Required packages: ggplot2, dplyr, scales, ggrepel
# Output: Images/dfai_*.png (800px wide, white background)
# =============================================================================
source("Scripts/theme_inphronesys.R")
library(ggplot2)
library(dplyr)
library(scales)
img_dir <- "Images"
# =============================================================================
# IMAGE 1: dfai_part_count.png (800x400)
# DFMA before/after bar chart — consumer hairdryer fastener count
# =============================================================================
df_parts <- data.frame(
design = factor(
c("Legacy design\n(pre-DFMA)", "DFMA-redesigned"),
levels = c("Legacy design\n(pre-DFMA)", "DFMA-redesigned")
),
parts = c(9, 1),
bar_fill = c("legacy", "redesigned")
)
p1 <- ggplot(df_parts, aes(x = design, y = parts, fill = bar_fill)) +
geom_col(width = 0.5) +
geom_text(
aes(label = paste0(parts, " fastener", ifelse(parts > 1, "s", ""))),
vjust = -0.45, fontface = "bold", size = 6, color = iph_colors$dark
) +
scale_fill_manual(
values = c(legacy = iph_colors$lightgrey, redesigned = iph_colors$blue),
guide = "none"
) +
scale_y_continuous(limits = c(0, 11.5), breaks = NULL) +
labs(
title = "DFMA: A Design Problem, Not a Factory Problem",
subtitle = "Illustrative DFMA part-count reduction (Boothroyd & Dewhurst)",
caption = "Boothroyd & Dewhurst: 20–50% cost reduction is a design problem, not a factory problem.",
x = NULL, y = NULL
) +
theme_inphronesys(grid = "none")
ggsave(file.path(img_dir, "dfai_part_count.png"), p1,
width = 8, height = 4, dpi = 100, bg = "white")
# =============================================================================
# IMAGE 2: dfai_funnel.png (800x500)
# Pilot-to-production attrition funnel
# =============================================================================
steps <- c("GenAI pilots\nlaunched", "Still active\nafter 6 months", "Reach\nproduction scale")
pcts <- c(100, 49, 4)
df_funnel <- data.frame(
step = factor(steps, levels = rev(steps)),
pct = pcts
)
p2 <- ggplot() +
geom_col(data = df_funnel, aes(y = step, x = 100),
fill = iph_colors$lightgrey, width = 0.55) +
geom_col(data = df_funnel, aes(y = step, x = pct),
fill = iph_colors$blue, width = 0.55) +
geom_text(data = df_funnel, aes(y = step, x = pct, label = paste0(pct, "%")),
hjust = -0.25, fontface = "bold", size = 5.5, color = iph_colors$dark) +
annotate("text", y = 2, x = 53,
label = "Ambiguous requirements,\nfragmented data",
hjust = 0, size = 3.5, color = iph_colors$grey,
lineheight = 1.25, fontface = "italic") +
annotate("text", y = 1, x = 8,
label = "No observability,\nunclear ownership",
hjust = 0, size = 3.5, color = iph_colors$grey,
lineheight = 1.25, fontface = "italic") +
scale_x_continuous(limits = c(0, 130), breaks = NULL) +
labs(
title = "The GenAI Pilot Graveyard",
subtitle = "Of every 100 AI pilots launched, only 4 reach production scale",
caption = "Source: BCG AI Adoption Survey, 2024",
x = NULL, y = NULL
) +
theme_inphronesys(grid = "none") +
theme(axis.text.y = element_text(size = 12, color = iph_colors$dark))
ggsave(file.path(img_dir, "dfai_funnel.png"), p2,
width = 8, height = 5, dpi = 100, bg = "white")
# =============================================================================
# IMAGE 3: dfai_principles_card.png (800x700)
# The 7 DFAI principles comparison card
# =============================================================================
principles <- data.frame(
num = 1:7,
dfma = c(
"Poka-yoke (mistake-proofing)",
"Standardize parts & processes",
"Single assembly direction",
"Machine-readable geometry",
"Self-locating features",
"Standardized fasteners",
"Design for ease of inspection"
),
dfai = c(
"Eliminate ambiguity",
"Externalize tribal knowledge",
"Chunk and label",
"Prefer structured over narrative",
"Make state explicit",
"Standardize the human\u2194agent handoff",
"Observability first"
)
)
row_h <- 0.1
p3 <- ggplot() +
annotate("rect", xmin = 0, xmax = 1, ymin = 0.9, ymax = 1.0,
fill = iph_colors$blue, color = NA) +
annotate("text", x = 0.5, y = 0.95,
label = "Design for AI: The 7 Principles",
hjust = 0.5, vjust = 0.5, size = 7, fontface = "bold", color = "white") +
annotate("rect", xmin = 0, xmax = 0.47, ymin = 0.8, ymax = 0.9,
fill = iph_colors$navy, color = NA) +
annotate("text", x = 0.235, y = 0.85,
label = "DFMA Principle", hjust = 0.5, vjust = 0.5,
size = 4.5, fontface = "bold", color = "white") +
annotate("rect", xmin = 0.47, xmax = 0.53, ymin = 0.8, ymax = 0.9,
fill = iph_colors$navy, color = NA) +
annotate("text", x = 0.5, y = 0.85, label = "\u2192",
hjust = 0.5, vjust = 0.5, size = 5, color = "white") +
annotate("rect", xmin = 0.53, xmax = 1.0, ymin = 0.8, ymax = 0.9,
fill = iph_colors$navy, color = NA) +
annotate("text", x = 0.765, y = 0.85,
label = "DFAI Rule", hjust = 0.5, vjust = 0.5,
size = 4.5, fontface = "bold", color = "white")
for (i in 1:7) {
row_top <- 1.0 - (i + 1) * row_h
row_bottom <- row_top - row_h
row_mid <- (row_top + row_bottom) / 2
row_fill <- if (i %% 2 == 0) iph_colors$lightgrey else "#ffffff"
p3 <- p3 +
annotate("rect", xmin = 0, xmax = 1,
ymin = row_bottom, ymax = row_top, fill = row_fill, color = NA) +
annotate("point", x = 0.04, y = row_mid, size = 8,
color = iph_colors$blue, shape = 16) +
annotate("text", x = 0.04, y = row_mid,
label = as.character(principles$num[i]),
hjust = 0.5, vjust = 0.5, size = 3.8,
fontface = "bold", color = "white") +
annotate("text", x = 0.10, y = row_mid,
label = principles$dfma[i], hjust = 0, vjust = 0.5,
size = 3.8, color = iph_colors$dark) +
annotate("text", x = 0.5, y = row_mid, label = "\u2192",
hjust = 0.5, vjust = 0.5, size = 4.5, color = iph_colors$grey) +
annotate("text", x = 0.56, y = row_mid,
label = principles$dfai[i], hjust = 0, vjust = 0.5,
size = 3.8, fontface = "bold", color = iph_colors$blue)
}
p3 <- p3 +
annotate("rect", xmin = 0, xmax = 1, ymin = 0, ymax = 0.1,
fill = iph_colors$lightgrey, color = NA) +
annotate("text", x = 0.5, y = 0.05,
label = "inphronesys.com \u00b7 2026",
hjust = 0.5, vjust = 0.5, size = 3.5, color = iph_colors$grey) +
coord_cartesian(xlim = c(0, 1), ylim = c(0, 1), expand = FALSE) +
theme_void()
ggsave(file.path(img_dir, "dfai_principles_card.png"), p3,
width = 8, height = 7, dpi = 100, bg = "white")
# =============================================================================
# IMAGE 4: dfai_quadrant.png (800x500)
# 2x2 AI-readiness quadrant
# =============================================================================
library(ggrepel)
df_quad <- data.frame(
label = c(
"Slack message", "Hallway conversation", "Meeting minutes", "Email thread",
"README / SOP", "Well-written\nAPI docs", "Master data\nrecord",
"JSON schema /\nOpenAPI spec"
),
structured = c(18, 5, 38, 28, 65, 85, 80, 95),
explicit = c(22, 5, 45, 32, 63, 90, 88, 95),
priority = c(FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE)
)
p4 <- ggplot(df_quad, aes(x = structured, y = explicit)) +
annotate("rect", xmin = 50, xmax = 100, ymin = 50, ymax = 100,
fill = iph_colors$blue, alpha = 0.08) +
annotate("rect", xmin = 0, xmax = 50, ymin = 0, ymax = 50,
fill = iph_colors$lightgrey, alpha = 0.6) +
annotate("text", x = 75, y = 97, label = "AI-ready",
hjust = 0.5, vjust = 1, size = 5, fontface = "bold",
color = iph_colors$blue) +
annotate("text", x = 25, y = 3, label = "AI-hostile",
hjust = 0.5, vjust = 0, size = 5, fontface = "bold",
color = iph_colors$grey) +
geom_vline(xintercept = 50, linetype = "dashed",
color = iph_colors$grey, linewidth = 0.5, alpha = 0.7) +
geom_hline(yintercept = 50, linetype = "dashed",
color = iph_colors$grey, linewidth = 0.5, alpha = 0.7) +
geom_point(aes(color = priority, size = priority), alpha = 0.9) +
scale_color_manual(
values = c("FALSE" = iph_colors$navy, "TRUE" = iph_colors$blue),
guide = "none"
) +
scale_size_manual(values = c("FALSE" = 3, "TRUE" = 4), guide = "none") +
geom_text_repel(aes(label = label), size = 3.4, color = iph_colors$dark,
segment.color = iph_colors$grey, segment.size = 0.3,
max.overlaps = 15, box.padding = 0.5, seed = 42,
lineheight = 0.9) +
scale_x_continuous(limits = c(0, 100), breaks = c(8, 92),
labels = c("Narrative", "Structured")) +
scale_y_continuous(limits = c(0, 100), breaks = c(8, 92),
labels = c("Implicit", "Explicit")) +
labs(
title = "How AI-Ready Is Your Information?",
subtitle = "Documents and artifacts mapped by structure and explicitness",
x = NULL, y = NULL
) +
theme_inphronesys(grid = "none") +
theme(
axis.text.x = element_text(size = 12, color = iph_colors$dark, face = "bold"),
axis.text.y = element_text(size = 12, color = iph_colors$dark, face = "bold")
)
ggsave(file.path(img_dir, "dfai_quadrant.png"), p4,
width = 8, height = 5, dpi = 100, bg = "white")
# =============================================================================
# IMAGE 5: dfai_audit.png (800x500)
# 5-step DFAI audit — two columns (individuals + teams)
# =============================================================================
ind_steps <- c(
"List your last\n10 prompts",
"Find the most\nambiguous",
"Rewrite: scope +\nformat + exclusions",
"Move implicit\ncontext \u2192 explicit",
"Save as\ntemplate"
)
team_steps <- c(
"Pick one high-\nvolume process",
"List implicit\ndecisions",
"Score: rule-able?\ny / n / maybe",
"Find 3 '9-fastener\nmoments'",
"Redesign one\nthis quarter"
)
n_steps <- 5
cx_ind <- 0.165; tx_ind <- 0.215
cx_team <- 0.665; tx_team <- 0.715
top_y <- 0.695; step_h <- 0.135
p5 <- ggplot() +
annotate("rect", xmin = 0, xmax = 1, ymin = 0.9, ymax = 1.0,
fill = iph_colors$blue, color = NA) +
annotate("text", x = 0.5, y = 0.95,
label = "Run this DFAI audit this week",
hjust = 0.5, vjust = 0.5, size = 6.5, fontface = "bold", color = "white") +
annotate("rect", xmin = 0.02, xmax = 0.48, ymin = 0.82, ymax = 0.90,
fill = iph_colors$navy, color = NA) +
annotate("text", x = 0.25, y = 0.86, label = "For individuals",
hjust = 0.5, vjust = 0.5, size = 4.5, fontface = "bold", color = "white") +
annotate("rect", xmin = 0.52, xmax = 0.98, ymin = 0.82, ymax = 0.90,
fill = iph_colors$navy, color = NA) +
annotate("text", x = 0.75, y = 0.86, label = "For teams",
hjust = 0.5, vjust = 0.5, size = 4.5, fontface = "bold", color = "white") +
annotate("rect", xmin = 0.02, xmax = 0.48, ymin = 0.04, ymax = 0.82,
fill = iph_colors$light, color = NA) +
annotate("rect", xmin = 0.52, xmax = 0.98, ymin = 0.04, ymax = 0.82,
fill = iph_colors$light, color = NA)
for (i in seq_len(n_steps)) {
y_pos <- top_y - (i - 1) * step_h
p5 <- p5 +
annotate("point", x = cx_ind, y = y_pos, size = 9,
color = iph_colors$blue, shape = 16) +
annotate("text", x = cx_ind, y = y_pos, label = as.character(i),
hjust = 0.5, vjust = 0.5, size = 4, fontface = "bold", color = "white") +
annotate("text", x = tx_ind, y = y_pos, label = ind_steps[i],
hjust = 0, vjust = 0.5, size = 3.4,
color = iph_colors$dark, lineheight = 1.15) +
annotate("point", x = cx_team, y = y_pos, size = 9,
color = iph_colors$blue, shape = 16) +
annotate("text", x = cx_team, y = y_pos, label = as.character(i),
hjust = 0.5, vjust = 0.5, size = 4, fontface = "bold", color = "white") +
annotate("text", x = tx_team, y = y_pos, label = team_steps[i],
hjust = 0, vjust = 0.5, size = 3.4,
color = iph_colors$dark, lineheight = 1.15)
if (i < n_steps) {
y_from <- y_pos - 0.04; y_to <- y_pos - step_h + 0.04
p5 <- p5 +
annotate("segment", x = cx_ind, xend = cx_ind, y = y_from, yend = y_to,
arrow = arrow(length = unit(0.1, "cm"), type = "closed"),
color = iph_colors$grey, linewidth = 0.4) +
annotate("segment", x = cx_team, xend = cx_team, y = y_from, yend = y_to,
arrow = arrow(length = unit(0.1, "cm"), type = "closed"),
color = iph_colors$grey, linewidth = 0.4)
}
}
p5 <- p5 +
coord_cartesian(xlim = c(0, 1), ylim = c(0, 1), expand = FALSE) +
theme_void()
ggsave(file.path(img_dir, "dfai_audit.png"), p5,
width = 8, height = 5, dpi = 100, bg = "white")
cat("\nAll 5 DFAI images generated successfully.\n")
Interactive Dashboard
Assess where you stand on all 7 DFAI principles — get your weighted Readiness Score (0–100) and targeted recommendations for your two weakest areas.
Interactive Dashboard
Explore the data yourself — adjust parameters and see the results update in real time.
References
- Boothroyd, G., & Dewhurst, P. (1994). Product Design for Manufacture and Assembly. Marcel Dekker.
- Dewhurst, P., & Boothroyd, G. (1987). Design for Assembly in Action. Assembly Engineering, 30(1), 64–68.
- Anthropic. (2025). Effective Context Engineering for AI Agents. Anthropic Engineering Blog.
- Anthropic. (2024). Building Effective AI Agents. Anthropic Research.
- Howard, J. (2024). llms.txt: A proposal. Answer.AI. [llmstxt.org]
- Weng, L. (2023). Prompt Engineering. Lil’Log. [lilianweng.github.io]
- arXiv 2505.11679 (2025). Ambiguity in LLMs is a concept missing problem. Hu et al.
- arXiv 2512.12791 (2024). Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems.
- Deloitte. (2024–25). Procurement Data Quality Standards for AI Adoption.
- Gartner (via Lucid.co, 2025). Organizations will abandon 60% of AI projects through 2026 without AI-ready data.
- Lucid.co. (2025). AI Readiness Report 2025. [lucid.co/ai-readiness]
- BCG. (2024). Where’s the Value in AI? Only 4% of companies have developed AI capabilities to consistently generate significant value.
- Klein, G., & Hoffman, R. (2025). Human-AI teaming: interface consistency and collaborative performance.
- Fern. (2026). How to write LLM-friendly documentation.
- Alliance for Lifetime Income. (2024). Peak 65: 11,200 Americans turn 65 per day through 2027. [protectedincome.org/peak65]
Related posts on inphronesys.com:
- Prompting Just Split Into 4 Different Skills — Here’s How to Master Each One — for the taxonomy of prompting disciplines (Prompt Craft, Context Engineering, Intent Engineering, Specification Engineering)
- Anthropic Just Killed One of Its Own Prompting Tricks — for the 2020–2026 history of prompting techniques
- The $50,000 Prompt: How McKinsey Frameworks Turn AI Into Your Best Supply Chain Consultant — for using structured consulting frameworks to improve prompt quality
Schreibe einen Kommentar