A model scored 62.1 on SWE-bench Pro. One outlet ran the headline "beats GPT-5.5." Another ran "trails Claude by 7 points." Same model. Same benchmark. Same number. Opposite story. That is the whole problem with how we read AI benchmarks right now, and GLM-5.2 is the cleanest example I’ve seen in months.
Here’s the setup. On 13 June 2026, Z.ai (the Beijing lab formerly known as Zhipu AI) released GLM-5.2 under an MIT license. Open weights. Anyone can download them. Within days it sat at the top of the open-weight leaderboards, won Design Arena outright, and undercut GPT-5.5 on output-token price by roughly 7x. The press reached for the obvious comparison: a new DeepSeek moment. A Chinese challenger crashing the closed frontier party.
That part is real. What’s also real is that the moment you line up the benchmark tables side by side, they start arguing with each other. This post is about that argument, and what a supply chain or operations team should actually do with it.
If you’re weighing an LLM for document extraction, supplier classification, or contract review, this matters to you directly. The score you copy off a leaderboard to justify the choice can be off by ten points before the quarter ends, and on one benchmark in this very post it already moved while I was writing. Here is how to tell the signal from the marketing.
What GLM-5.2 actually is
Strip the hype and the facts are still impressive. GLM-5.2 is a Mixture-of-Experts model with around 40B active parameters and a 1,000,000-token context window (up from 256K in GLM-5.1). The weights live on Hugging Face under zai-org and on ModelScope. API pricing runs $1.40 per million input tokens, $4.40 per million output tokens, and $0.26 for a cache hit.
On the headline ranking, the Artificial Analysis Intelligence Index v4.1, GLM-5.2 scores 51. That puts it behind the closed frontier (Claude Fable 5 at 60, Claude Opus 4.8 at 56, GPT-5.5 at 55) but ahead of every other open-weight model by a clear margin. Artificial Analysis calls it the #1 open-weight model and 4th overall.
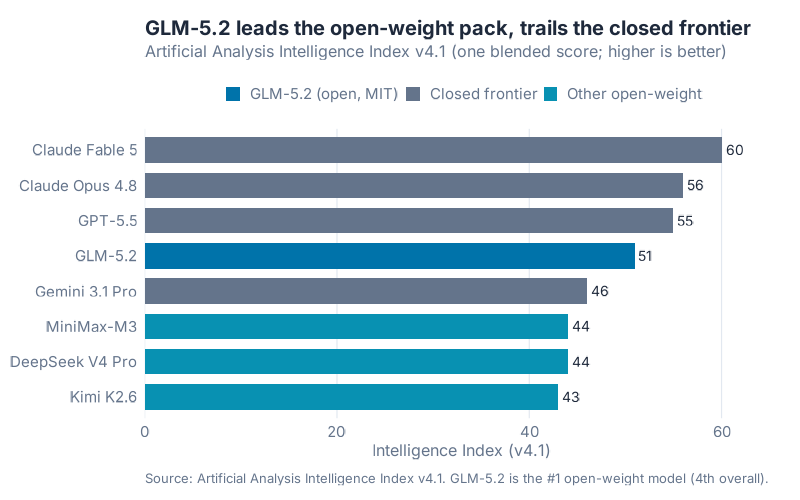
So far, so clean. One number, one ranking, one tidy story. Now watch it fall apart.
The same score, two headlines
SWE-bench Pro tests whether a model can fix real GitHub bugs: patches that have to pass actual tests, not multiple-choice trivia. GLM-5.2 scores 62.1. That number doesn’t move. What moves is who you put next to it.
Put GLM-5.2 next to GPT-5.5 (58.6) and GLM-5.2 wins. Put it next to Claude Opus 4.8 (69.2, vendor-reported) and GLM-5.2 loses by 7 points. Drop Opus from the table entirely, which several write-ups did, and GLM-5.2 "leads the frontier." Nothing about the model changed. The table did.
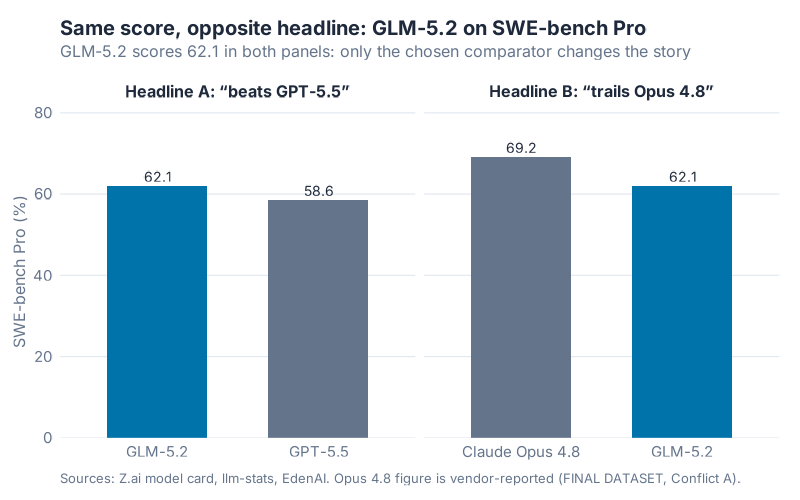
What jumped out at me wasn’t the cherry-picking. It was how a second sleight of hand snuck in alongside it. Some coverage ran a "0.7 points from the king" headline, which sounds like the SWE-bench Pro gap closing to almost nothing. It isn’t. That 0.7 comes from a different benchmark, FrontierSWE, where GLM-5.2 scores 74.4 against Opus 4.8’s 75.1. Two separate evals got collapsed into one triumphant number. A reader skimming the headline would never know.
It gets worse when you ask who ran the test. On SWE-bench Pro, a tracker that re-runs everything on one standardized, independent harness tops out at 59.1% (that’s GPT-5.4), while the best vendor-reported figure in the table is Opus 4.8 at 69.2%. Those are different models, which is exactly the point: most published benchmark tables quietly mix standardized numbers with vendor-reported ones, and a 10-point reporting gap on the same benchmark tells you those two regimes are not the same measurement. And here’s the kicker that the data-integrity part of my brain keeps circling back to: 48 hours after launch, no independent third party had reproduced GLM-5.2’s SWE-bench Pro score at all. The headline numbers were vendor-reported, and at least one commentator flagged that some quoted figures might be conflating GLM-5.2 with GLM-5.1 (which scored 58.4).
I’ll say it plainly. A benchmark number with no named harness and no independent reproduction is a marketing claim wearing a lab coat.
The conflicts don’t stop at SWE-bench
Once you start looking, the disagreements are everywhere in this release.
Terminal-Bench 2.1 (autonomous coding in a real terminal loop) shows up as 78, 81.0, or 82.7 for GLM-5.2 depending on the source. Artificial Analysis lists 78. The Z.ai model card lists 81.0 on the Terminus-2 harness and 82.7 as "best reported." Same model, same benchmark version, a 5-point spread that comes entirely from the agent harness wrapped around it.
Even the parameter count can’t agree with itself. Most secondary coverage says 744B total. Z.ai’s own Hugging Face card says 753B. When the vendor and the aggregators can’t settle on how big the model is, treat the third-decimal-place benchmark precision with the skepticism it deserves.
Then there’s the benchmark that moved while I was writing this. GDPval-AA scores models on real, economically valuable knowledge work across 44 occupations, and it’s the closest thing on this list to "can it do a useful job." On launch day, 13 June, the leaderboard showed GLM-5.2 at 1524, nosing ahead of GPT-5.5 at 1514, with Opus 4.8 not yet listed. Ten days later the same page reads differently: Opus 4.8 now sits on top at 1605, GLM-5.2 has settled at 1520, and GPT-5.5 at 1496. Nobody retrained a model. The leaderboard simply added results and ran more occupations. A table you screenshotted for a vendor pitch on June 13 was already wrong by June 23. That is not a knock on GDPval. It’s the honest texture of a live benchmark, and it’s the single best argument for checking the source yourself rather than trusting a number someone pasted into a slide last week.
Here’s the comparison table, with the conflicts left in rather than smoothed over. The ranges are the point, not a typo.
| Benchmark (what it tests) | GLM-5.2 | GPT-5.5 | Claude Opus 4.8 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro (real GitHub bug fixes) | 62.1 | 58.6 | 69.2 (vendor) | n/a |
| Terminal-Bench 2.1 (autonomous agent coding) | 78 / 81.0 / 82.7 | 84.0 | 85.0 | 74.0 |
| FrontierSWE (frontier SW-engineering tasks) | 74.4 | 72.6 | 75.1 | n/a |
| GDPval-AA v2 (economically valuable tasks, ELO; live 23 Jun) | 1520 | 1496 | 1605 | n/a |
| GPQA-Diamond (graduate science Q&A) | 91.2 | n/a | 93.6 | n/a |
| AIME 2026 (competition math) | 99.2 | n/a | n/a | n/a |
| MCP-Atlas (tool use / agent orchestration) | 76.8 | n/a | 77.8 | n/a |
An "n/a" means no verifiable source reported that pairing. I’d rather show you a gap than invent a number to fill it.
Why the high scores tell you less every quarter
Look at the bottom of that table. GLM-5.2 scores 99.2 on AIME 2026 and 91.2 on GPQA-Diamond. Those are extraordinary numbers, and they are also nearly useless for telling frontier models apart. When a benchmark sits near its ceiling, every strong model clusters in the same two or three points, and the ranking becomes noise. Competition math and graduate science multiple-choice are largely solved at the top. They don’t separate the contenders anymore.
This is why SWE-bench Pro exists in the first place. Scale AI built it because models "have likely seen the evaluation code during training" on the older public benchmarks. So SWE-bench Pro uses legally inaccessible private and commercial repositories: 731 public, 858 held-out, and 276 commercial tasks, 1,865 in total across 41 repos. The gap between public-set and held-out scores is the contamination signal. That is a benchmark designed around the assumption that the models have already memorized the easy version.
The leaderboards know this too, which is why they keep moving the goalposts. Artificial Analysis shifted its Intelligence Index to v4.1 explicitly weighted toward agentic workloads, because the older knowledge benchmarks had saturated. That’s an honest fix. It also means a model’s rank can change without the model changing at all. Re-weight the blend, reshuffle the table.
There’s a structural lesson here. A single blended score is a convenience, not a truth. It hides where a model is strong and where it’s weak, and the weighting choices behind it are editorial decisions that move ranks on their own.
Where the cheap-and-strong story holds up
I’ve spent most of this post poking holes, so let me give GLM-5.2 its due, because the value case is the part that survives the scrutiny.
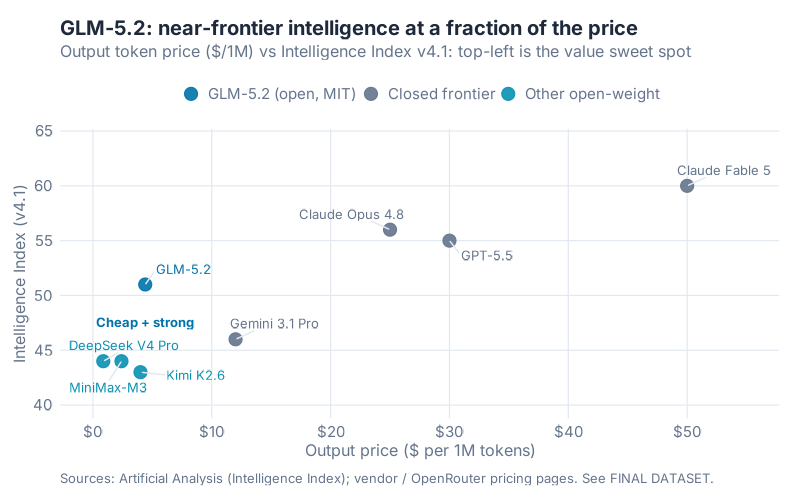
Plot output price against the Intelligence Index and GLM-5.2 lands in the top-left corner almost alone. It delivers an Intelligence Index of 51 at $4.40 per million output tokens. Opus 4.8 scores 56 at $25. GPT-5.5 scores 55 at $30. On output tokens, the closed leaders cost about 7 times more for roughly 5 more points on a blended index whose weighting is itself debatable. (On a balanced input-output workload the gap narrows to around 5 times, still a wide margin.)
That tradeoff doesn’t disappear when you discount the benchmarks. If anything it gets more interesting, because the price gap is measured in dollars you actually pay, while the capability gap is measured in index points whose meaning we’ve just spent two sections questioning.
The "new DeepSeek moment" question
Is GLM-5.2 a watershed for AI the way DeepSeek was? Partly. The thing that matters isn’t the leaderboard rank. It’s the license. An MIT-licensed model that lands one rung below the closed frontier, that you can download and run inside your own walls, changes the negotiating position of every buyer in the market. You no longer have to choose between frontier-adjacent capability and control over your data. For a while you did.
The hype overshoots in the usual direction. "Beats Claude" makes a better headline than "lands a competitive open-weight option at a fraction of the price, pending independent reproduction." The second sentence is the true one. It’s also the one nobody reposts.
What this means if you’re choosing AI for operations
Here’s where it lands for anyone picking a model to run document extraction, supplier classification, demand-signal triage, or contract review. The leaderboard rank is the start of your due diligence, not the end of it.
Three things matter more than the headline ELO.
Total cost of ownership. For high-volume, well-scoped jobs (extraction, classification, routing), a cheap-but-strong model is often the right call even if it sits a few index points below the frontier. Do the arithmetic. At $4.40 versus $25 to $30 per million output tokens, the math changes fast at scale. The 5-point capability gap may be invisible on your actual task. The 7x cost gap shows up on every invoice.
Data residency. Open weights mean you can self-host, which matters when supplier data, pricing, or contracts can’t leave your tenancy. But read the fine print: there’s a documented data-risk flag on the Z.ai-hosted API endpoint specifically, tied to China jurisdiction. Self-hosting the MIT weights sidesteps that. Using the hosted API doesn’t. Those are two different products with the same name.
Task fit, proven on your own eval set. A benchmark tells you a model is in the conversation. Your own eval tells you whether it does your job. These are not the same question, and only one of them appears on a leaderboard.
Look for yourself
The single most useful habit you can build is checking the primary sources instead of the press release. Here are the live leaderboards, and what each one does and doesn’t measure:
- Artificial Analysis (https://artificialanalysis.ai): the blended Intelligence Index plus speed and price. Remember that the weighting is an editorial choice, and v4.1 tilted toward agentic work.
- LMArena / Chatbot Arena (https://lmarena.ai): blind human preference votes turned into ELO. It measures which answer people prefer, not which is correct, and it carries style and length bias.
- SWE-bench Pro (https://labs.scale.com/leaderboard/swe_bench_pro_public): real GitHub bug fixes on contamination-resistant repos. Public-set scores are still contamination-prone, and harness choices swing results 5 to 10 points.
- Terminal-Bench (https://www.tbench.ai): autonomous task completion in a real terminal. Highly sensitive to the agent harness, which is exactly why GLM-5.2 shows three different numbers.
- Design Arena (https://www.designarena.ai): human-preference ELO for generated web and UI design code. Aesthetic preference is subjective and says nothing about backend logic.
- GDPval (https://artificialanalysis.ai/evaluations/gdpval-aa): performance on real, economically valuable tasks across 44 occupations. Graded against expert deliverables on a sampled task set, "GDP-valuable" still isn’t your workflow.
When the model card and three aggregators disagree, the disagreement is the data. Read the spread, not the headline.
Interactive Dashboard
Explore the benchmark claims yourself: every score, every conflict, and a live link to each leaderboard so you can check the primary source in one click.
Interactive Dashboard
Explore the data yourself — adjust parameters and see the results update in real time.
Your next steps this week
- Build a 20-task eval set from your own work. Pull real examples of the job you’d hand an LLM (your invoices, your supplier emails, your contract clauses) and write the correct answer for each. This is the only leaderboard that ranks models on your problem.
- Run GLM-5.2 and your incumbent model against that set side by side. The weights are on Hugging Face (https://huggingface.co/zai-org). Compare accuracy and cost on the same 20 tasks, not on someone else’s benchmark.
- Price the full workload, not the per-token rate. Multiply your realistic monthly token volume by $4.40 output and $1.40 input for GLM-5.2, then against your current model’s rates. Put the two annual figures next to each other before anyone debates capability.
- Decide self-host versus API on data residency, not convenience. If supplier or pricing data can’t leave your tenancy, the self-hosted MIT weights and the China-jurisdiction hosted API are different risk profiles. Pick deliberately.
- Bookmark two leaderboards and re-check them quarterly. Artificial Analysis and SWE-bench Pro update often, and re-weightings move ranks without any model changing. Knowing when the methodology shifted is half of reading the rank correctly.
If you’ve read my earlier posts on demand forecasting, the throughline is the same: a single headline metric (MAPE, an ELO, an index) flatters whoever chose it. The discipline is in the eval you build, not the score you’re handed.
Show R Code
# =============================================================================
# generate_glm_benchmark_images.R
# Charts for the GLM-5.2 benchmark-skepticism blog post (2026-06-23)
# All numbers come from the FINAL DATASET:
# Drafts/2026-06-23_GLM_5_2_Benchmark_FINAL_DATASET.md
# Run from project root: Rscript Scripts/generate_glm_benchmark_images.R
# =============================================================================
source("Scripts/theme_inphronesys.R")
library(ggplot2)
library(dplyr)
library(scales)
dir.create("Images", showWarnings = FALSE)
# Type colors: GLM-5.2 = brand blue (the hero); closed leaders = slate grey;
# other open-weight peers = teal.
col_glm <- iph_colors$blue
col_closed <- iph_colors$grey
col_open <- iph_colors$teal
# =============================================================================
# DATA — Artificial Analysis Intelligence Index v4.1 + output price ($/1M)
# =============================================================================
models <- tibble::tribble(
~model, ~intelligence, ~out_price, ~type,
"Claude Fable 5", 60, 50.00, "Closed",
"Claude Opus 4.8", 56, 25.00, "Closed",
"GPT-5.5", 55, 30.00, "Closed",
"GLM-5.2", 51, 4.40, "GLM-5.2",
"Gemini 3.1 Pro", 46, 12.00, "Closed",
"MiniMax-M3", 44, 2.40, "Open",
"DeepSeek V4 Pro", 44, 0.87, "Open",
"Kimi K2.6", 43, 4.00, "Open"
)
fill_scale <- scale_fill_manual(
values = c("GLM-5.2" = col_glm, "Closed" = col_closed, "Open" = col_open),
breaks = c("GLM-5.2", "Closed", "Open"),
labels = c("GLM-5.2 (open, MIT)", "Closed frontier", "Other open-weight")
)
color_scale <- scale_color_manual(
values = c("GLM-5.2" = col_glm, "Closed" = col_closed, "Open" = col_open),
breaks = c("GLM-5.2", "Closed", "Open"),
labels = c("GLM-5.2 (open, MIT)", "Closed frontier", "Other open-weight")
)
# =============================================================================
# CHART 1 — Intelligence Index bar chart
# =============================================================================
df1 <- models %>% mutate(model = reorder(model, intelligence))
p1 <- ggplot(df1, aes(intelligence, model, fill = type)) +
geom_col(width = 0.72) +
geom_text(aes(label = intelligence), hjust = -0.25,
size = 3.6, color = iph_colors$dark, family = "Inter") +
fill_scale +
scale_x_continuous(limits = c(0, 66), expand = expansion(mult = c(0, 0))) +
labs(
title = "GLM-5.2 leads the open-weight pack, trails the closed frontier",
subtitle = "Artificial Analysis Intelligence Index v4.1 (one blended score; higher is better)",
x = "Intelligence Index (v4.1)", y = NULL, fill = NULL,
caption = "Source: Artificial Analysis Intelligence Index v4.1. GLM-5.2 is the #1 open-weight model (4th overall)."
) +
theme_inphronesys(grid = "x") +
theme(legend.position = "top")
ggsave("https://inphronesys.com/wp-content/uploads/2026/06/glm_intelligence_index.png", p1,
width = 8, height = 5, dpi = 100, bg = "white")
# =============================================================================
# CHART 2 — Cost vs capability scatter (output $/1M vs Intelligence Index)
# =============================================================================
p2 <- ggplot(models, aes(out_price, intelligence, color = type)) +
geom_point(size = 4, alpha = 0.9) +
ggrepel::geom_text_repel(
aes(label = model), size = 3.4, family = "Inter",
seed = 42, box.padding = 0.5, min.segment.length = 0,
segment.color = iph_colors$lightgrey, show.legend = FALSE
) +
color_scale +
scale_x_continuous(labels = label_dollar(suffix = ""),
limits = c(0, 55), breaks = seq(0, 50, 10)) +
scale_y_continuous(limits = c(40, 64)) +
annotate("text", x = 4.4, y = 47.5, label = "Cheap + strong",
color = col_glm, size = 3.3, fontface = "bold", family = "Inter") +
labs(
title = "GLM-5.2: near-frontier intelligence at a fraction of the price",
subtitle = "Output token price ($/1M) vs Intelligence Index v4.1: top-left is the value sweet spot",
x = "Output price ($ per 1M tokens)", y = "Intelligence Index (v4.1)", color = NULL,
caption = "Sources: Artificial Analysis (Intelligence Index); vendor / OpenRouter pricing pages. See FINAL DATASET."
) +
theme_inphronesys(grid = "xy") +
theme(legend.position = "top")
ggsave("https://inphronesys.com/wp-content/uploads/2026/06/glm_cost_vs_capability.png", p2,
width = 8, height = 5, dpi = 100, bg = "white")
# =============================================================================
# CHART 3 — Same benchmark, opposite headline (SWE-bench Pro, GLM-5.2 = 62.1)
# =============================================================================
# GLM-5.2 scores the SAME 62.1 in both panels; only the chosen comparator flips
# the narrative from "GLM wins" to "Claude leads by 7 points".
df3 <- tibble::tribble(
~framing, ~model, ~score, ~hero,
"Headline A: “beats GPT-5.5”", "GLM-5.2", 62.1, TRUE,
"Headline A: “beats GPT-5.5”", "GPT-5.5", 58.6, FALSE,
"Headline B: “trails Opus 4.8”","GLM-5.2", 62.1, TRUE,
"Headline B: “trails Opus 4.8”","Claude Opus 4.8", 69.2, FALSE
)
df3$framing <- factor(df3$framing,
levels = c("Headline A: “beats GPT-5.5”", "Headline B: “trails Opus 4.8”"))
p3 <- ggplot(df3, aes(model, score, fill = hero)) +
geom_col(width = 0.62) +
geom_text(aes(label = sprintf("%.1f", score)), vjust = -0.4,
size = 3.6, color = iph_colors$dark, family = "Inter") +
facet_wrap(~framing, scales = "free_x") +
scale_fill_manual(values = c("TRUE" = col_glm, "FALSE" = col_closed), guide = "none") +
scale_y_continuous(limits = c(0, 80), expand = expansion(mult = c(0, 0.02))) +
labs(
title = "Same score, opposite headline: GLM-5.2 on SWE-bench Pro",
subtitle = "GLM-5.2 scores 62.1 in both panels: only the chosen comparator changes the story",
x = NULL, y = "SWE-bench Pro (%)",
caption = "Sources: Z.ai model card, llm-stats, EdenAI. Opus 4.8 figure is vendor-reported (FINAL DATASET, Conflict A)."
) +
theme_inphronesys(grid = "y")
ggsave("https://inphronesys.com/wp-content/uploads/2026/06/glm_swebench_conflict.png", p3,
width = 8, height = 5, dpi = 100, bg = "white")
cat("Done. Wrote 3 PNGs to Images/ (prefix glm_).\n")
References
- Z.ai, "GLM-5.2" model card and benchmark table, Hugging Face (https://huggingface.co/blog/zai-org/glm-52-blog)
- Artificial Analysis, "GLM-5.2 is the new leading open-weights model on the Artificial Analysis Intelligence Index" (https://artificialanalysis.ai/articles/glm-5-2-is-the-new-leading-open-weights-model-on-the-artificial-analysis-intelligence-index)
- Artificial Analysis, "Intelligence Index v4.1" methodology (https://artificialanalysis.ai/articles/artificial-analysis-intelligence-index-v4-1)
- Scale AI, "SWE-bench Pro" (https://scale.com/blog/swe-bench-pro) and public leaderboard (https://scaleapi.github.io/SWE-bench_Pro-os/)
- Morph, SWE-bench Pro standardized vs vendor-reported tracker (https://www.morphllm.com/swe-bench-pro)
- EdenAI, "GLM-5.2 benchmark vs GPT-5.5, Claude Opus 4.8 and Gemini 3.1 Pro" (https://www.edenai.co/post/glm-5-2-benchmark-vs-gpt-5-5-claude-opus-4-8-and-gemini-3-1-pro)
- VentureBeat, "Z.ai’s open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost" (https://venturebeat.com/technology/z-ais-open-weights-glm-5-2-beats-gpt-5-5-on-multiple-long-horizon-coding-benchmarks-for-1-6th-the-cost)
- TechTimes, "GLM-5.2 open weights live; API use carries China data risk" (https://www.techtimes.com/articles/318543/20260617/glm-52-open-weights-live-top-coding-benchmark-api-use-carries-china-data-risk.htm)
- Design Arena leaderboard announcement (https://x.com/Designarena/status/2066940737011560652); Gizmochina coverage (https://www.gizmochina.com/2026/06/20/chinas-glm-5-2-beats-claude-fable-5-in-web-design-claims-no-1-spot/)
- llm-stats, Claude Opus 4.8 vs GLM-5.2 comparison (https://llm-stats.com/models/compare/claude-opus-4-8-vs-glm-5.2)
- GDPval, OpenAI (https://openai.com/index/gdpval/); arXiv paper (https://arxiv.org/abs/2510.04374)
Schreibe einen Kommentar