
Die ABC-Analyse ist eine weit verbreitete Methode im Einkaufscontrolling, die auf dem Pareto-Prinzip basiert. Dieses Prinzip, benannt nach dem italienischen Ökonomen Vilfredo Pareto, postuliert, dass 80% der Ergebnisse oft mit 20% der Ursachen erreicht werden können. Pareto entdeckte dies ursprünglich beim Studium von Einkommens- und Vermögensverteilungen in Europa, und seine Einsichten haben seither in vielen Bereichen, einschließlich des Supply Chain Managements, Anwendung gefunden.
In der Praxis hilft die ABC-Analyse Unternehmen dabei, ihre Ressourcen effizient zu allokieren, indem Güter oder Materialien in drei Kategorien eingeteilt werden: A für die wichtigsten, B für die weniger kritischen und C für die am wenigsten wichtigen Artikel. Diese Kategorisierung basiert auf dem Wert, den die Artikel für das Unternehmen darstellen, was häufig durch den Jahresverbrauchswert gemessen wird. Die A-Kategorie umfasst dabei typischerweise einen kleinen Anteil der Gesamtartikel, die aber den größten Teil zum Gesamtumsatz beitragen.
Während die ABC-Analyse eine robuste Methode für das Bestandsmanagement bietet, entstehen in der zunehmend datengetriebenen Geschäftswelt neue Ansätze, die möglicherweise effektivere Alternativen bieten. Ein solcher Ansatz ist das K-Means Clustering, ein populäres Verfahren aus dem Bereich des maschinellen Lernens. K-Means Clustering ermöglicht es, große Datenmengen in Cluster zu unterteilen, die intern homogen, jedoch extern heterogen sind. Das bedeutet, dass Artikel innerhalb eines Clusters ähnliche Eigenschaften aufweisen, sich aber deutlich von Artikeln in anderen Clustern unterscheiden.
Die Anwendung von K-Means Clustering im Einkaufscontrolling kann eine interessante und innovative Alternative zur klassischen ABC-Analyse darstellen. Indem Unternehmen ihre Artikel anhand von komplexeren Mustern und Beziehungen gruppieren, die über bloße Umsatzwerte hinausgehen, können sie tiefere Einblicke in ihre Bestände gewinnen. Dies kann zur Optimierung von Lagerhaltungsstrategien, zur Verbesserung der Lieferkettenleistung und zur effektiveren Kapitalbindung führen. Die K-Means Methode bietet somit eine dynamische Möglichkeit, die Herausforderungen moderner Lieferketten zu meistern und die Effizienz durch datengesteuerte Entscheidungen zu steigern.
Ich habe dazu ein sehr einfaches Beispiel für das K-MEANS Clustering erstellt.
Der R-Code dazu ist folgender:
library(readxl) # Bibliothek zu Laden von Excel Dateien
library(tidyverse) # Für Daten Manipulation und Visualisierung
# Einlesen der Daten
data <- read_excel("01_Data/Spend.xlsx")
# Normalisierung der Daten
data$Spend <- scale(data$Spend)
# k-means clustering
set.seed(123)
k <- 5 # Cluster können je nach Bedarf angepasst werden
clusters <- kmeans(data$Spend, centers=k, nstart=25)
# Cluster werden zum Datensatz hinzugefügt
data$Cluster <- clusters$cluster
# Graphische Darstellung
data$Supplier <- factor(data$Supplier, levels = data$Supplier[order(data$Cluster)])
ggplot(data, aes(x=Supplier, y=Spend, color=factor(Cluster))) +
geom_point(alpha=0.5) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
labs(color = "Cluster")
Der Code erstellt dann folgende Graphische Übersicht:
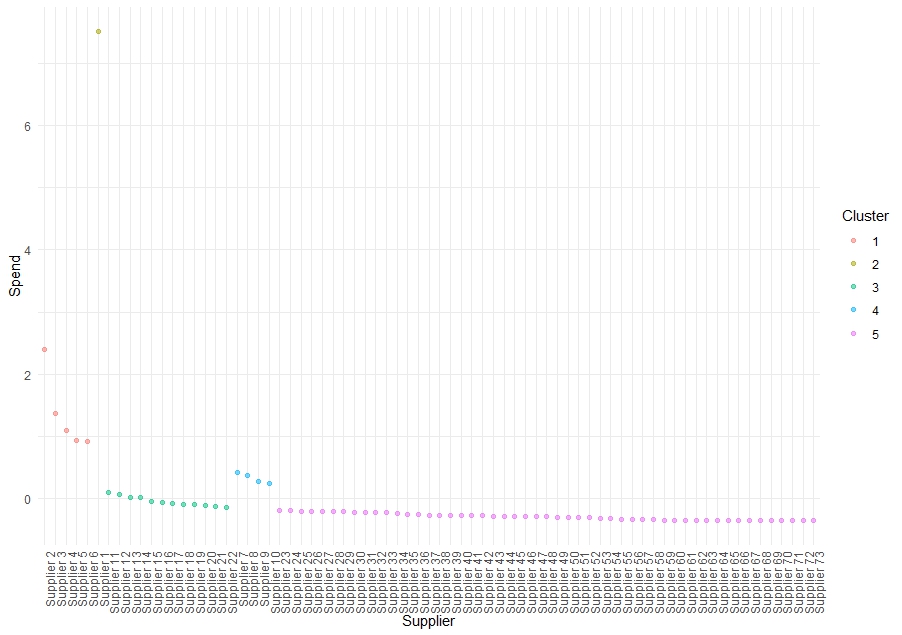
Im Beispiel werden die Lieferanten in 5 Cluster eingeteilt. Im Vergleich zur klassischen ABC-Analyse lässt die Clustering eine feinere Gliederung zu.
K-Means Clustering ist eine intuitive und effektive Methode zur Datenanalyse, die darauf abzielt, eine große Menge von Datenpunkten in mehrere Gruppen (oder Cluster) aufzuteilen, sodass Punkte in derselben Gruppe ähnlich und Punkte in verschiedenen Gruppen unterschiedlich sind. Dies geschieht in einem mehrstufigen Prozess:
- Initialisierung: Zuerst werden zufällig „K“ Zentren aus den Datenpunkten ausgewählt, wobei „K“ die Anzahl der Cluster ist, die man bilden möchte.
- Zuordnung: Jeder Datenpunkt im Datensatz wird dem nächstgelegenen Clusterzentrum zugeordnet. Die Nähe wird meistens durch die Distanz zwischen dem Datenpunkt und dem Clusterzentrum gemessen, wobei kürzere Distanzen eine größere Ähnlichkeit anzeigen.
- Aktualisierung: Nach der Zuordnung der Punkte werden die Zentren der Cluster aktualisiert, indem der Durchschnitt aller Punkte berechnet wird, die diesem Cluster zugeordnet sind. Dieser Schritt hilft dabei, die Clusterzentren besser zu positionieren.
- Wiederholung: Die Schritte 2 und 3 werden wiederholt, bis sich die Clusterzentren nicht mehr signifikant verschieben, was darauf hindeutet, dass ein Gleichgewicht erreicht wurde und die Cluster stabil sind.
Das Ergebnis ist eine Gruppierung der Datenpunkte, bei der ähnliche Punkte zusammengefasst und klar von anderen Gruppen unterschieden werden. K-Means ist besonders nützlich, um verborgene Muster in den Daten zu erkennen und diese effizient zu organisieren. Sie unterscheidet sich in Ihrem Vorgehen vom Pareto Ansatz und kann neue Muster erkennen.
Die Welt des Einkaufscontrollings entwickelt sich ständig weiter, und Methoden wie das K-Means Clustering zeigen, wie traditionelle Techniken durch den Einsatz von fortschrittlicher Datenanalyse ergänzt und verbessert werden können. Für Unternehmen, die an der Spitze der Innovation bleiben wollen, lohnt es sich, diese modernen datenwissenschaftlichen Ansätze zu erforschen und zu integrieren.
Die Methode lässt sich vor allem noch weiter ausbauen und bietet dadurch weitere Vorteile zur klassischen ABC-Analyse. Mehr dazu in einem weiteren Beitrag…
Schreibe einen Kommentar